While advances in microprocessor design continue to increase computing speed, improvements in data access speed of computing systems lag far behind. At the same time, data-intensive large-scale applications, such as information retrieval, computer animation, and big data analytics are emerging. Data access delay has become the vital performance bottleneck of high performance computing (HPC). Memory concurrency exists at each layer of modern memory hierarchies; however, conventional computing systems are primarily designed to improve CPU utilization and have inherent limitations in addressing the critical issue of data movement in HPC. In order to address the data movement bottleneck issues, this project extracts the general principles of parallel memory system by building on the new Concurrent-AMAT metric, a set of fresh theoretical results in data access concurrency, a series of recent successes in parallel I/O optimization, and new technology opportunities.
Current HPC systems do not fully recognize or exploit the concurrency that modern memory systems provide. The key new idea of CuPM is to establish a systematic way of exploring, enhancing, utilizing, and customizing memory concurrency to build effective memory systems. Data access concurrency is as important as data locality. Its importance is not only in concurrent hit, but, more importantly, is in hit-miss overlapping (latency hiding) and the balance of data locality, concurrency, and latency hiding. Locality is no longer the dominant metric for memory optimization. Data concurrence is application dependent. This project will be developed with two goals: to understand and reveal the memory concurrency and its properties, and to explore and utilize current memory concurrency. Figure 1 shows the system design of CuPM. The former is the foundation of the latter, and the latter is the verification of the former. The project is a challenging project involving fundamental issues in parallel computing, system software, and computing architecture, plus the concept of data access overlapping for latency hiding. Fortunately, we have developed a series of models, algorithms, methods, and mechanisms through years of effort. They have built a solid foundation for this project.
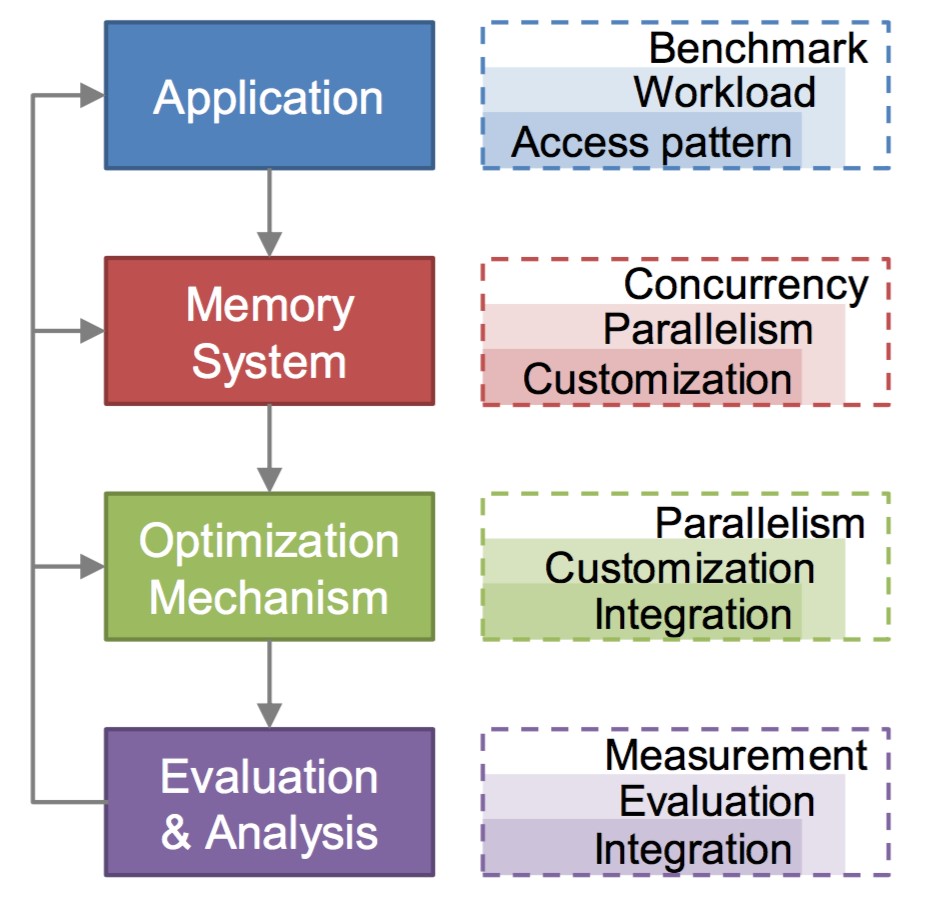
Figure 1. The system design of CuPM
Concurrent Average Memory Access Time (C-AMAT)
Memory systems can be characterized by space or time perspectives. From the space perspective, hierarchical structures are developed to explore the data access locality. From the time perspective, in each clock cycle, there could be many accesses being issued or returned in each layer of a memory system, and these concurrent data accesses can increase data access bandwidth and hide data access delay. Therefore, memory stall time is the combined result of locality and concurrency. The performance optimization of the modern memory system needs a comprehensive and accurate model integrating the effects of both locality and concurrency.
Concurrent Average Memory Access Time (C-AMAT) is an extension of average memory access time (AMAT). It considers concurrent data accesses and in doing so provides an accurate performance metric for the modern memory system. AMAT does not consider concurrent memory accesses, rather it assumes that memory accesses are sequential. C-AMAT integrates data concurrency into AMAT and unifies the influence of data locality and concurrency into one formula. Like AMAT, C-AMAT can be used recursively to measure the impact of locality and concurrency throughout all layers of the memory hierarchy and is widely used in the memory system design and optimization.
To cover the concurrent access properties of modern memory systems, C-AMAT introduces two new parameters, hit concurrency and miss concurrency. Rather than the traditional miss event occurred in the memory system, a "pure miss" is also introduced to better measure the parallel memory system's performance. Using pure misses, C-AMAT redefines miss rate and average miss penalty of AMAT to pure miss rate and pure average miss penalty. C-AMAT reveals two important facts. 1) Reducing the number of cache misses is not important for performance improvement but reducing the number of pure misses is. 2) Improving data locality may not always improve performance, thus optimizations should focus on providing a balanced improvement in both data locality and concurrency.
Layered Performance Matching (LPM)
The rationale of LPM is that the performance of each layer of a memory hierarchy should and can be optimized to closely match the request of the layer directly above it. The LPM model simultaneously considers both data access concurrency and locality. It reveals the fact that increasing the effective overlapping between hits and misses of the higher layer will alleviate the performance impact of the lower layer. LPM leads to improved measurement and analysis of data access delays and to a more effective and efficient method for obtaining a balanced memory system design and optimization. Figure 2 shows the details of LPM.
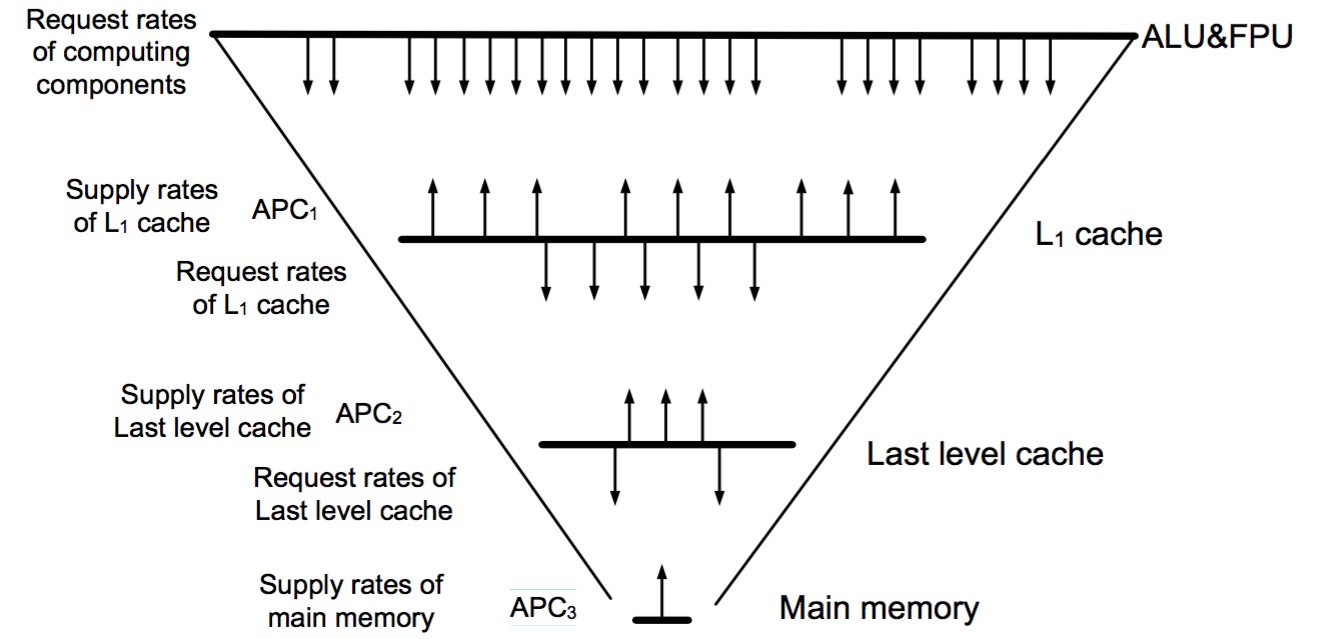
Figure 2. LPM (Layered Performance matching)
Memory Sluice Gate Theory and Pace-Matching Data Transfer
An algorithm is derived to achieve the "match" under the LPM approach. The Memory Sluice Gate Theory proves that under certain assumptions the LPM algorithm can find a solution. That is, with some engineering efforts, we can solve the memory-wall problem from an architectural perspective with the LPM matching approach. Sluice Gate Theory claims that memory hierarchy is a designed sluice to transfer data to computing units, and through multi-level sluice gate control we can match data flow demand with supply. Based on Sluice Gate Theory, a memory system is built to transfer data and to mask the performance gap between CPU and memory devices during the data transfer process. Sluice gates are designed to control data transfer at each memory layer dynamically under the C-AMAT model, and a global control algorithm is developed to match the data transfer request/supply at each memory layer thus matching the overall performance between the CPU and memory system under the LPM algorithm, which forms the pace-matching data transfer. In pace-matching data transfer, not only the traditional data access locality but also the data access concurrency is considered. The correctness of the theory is verified with rigorous mathematical proofs and extensive experimental testing.
The C-AMAT model and LPM method can be used directly in data access optimizations (see Liu and Sun 2019 for examples). They also can be used in different ways and different applications. For instance, C2- Bound (see Liu and Sun 2015 and 2017) is a data-driven analytical model that serves the purpose of optimizing many-core design. C2- Bound considers both memory capacity and data access concurrency. It utilizes the combined power of C-AMAT, and the well-known memory-bounded speedup model (Sun-Ni’s law) to facilitate computing tasks. Compared to traditional chip designs that lack the notion of memory capacity and concurrency, the C2- Bound model finds that memory bound factors significantly impact the optimal number of cores as well as their optimal silicon area allocations, especially for data-intensive applications with a non-parallelizable sequential portion. Experimental testing show, with C2- Bound, the design space of chip design can be narrowed down significantly up to four orders of magnitude. C2- Bound analytic results can be either used in reconfigurable hardware environments or, by software designers, applied to scheduling, partitioning, and allocating resources among diverse applications.
Dawei Wang and Xian-He Sun, "APC: A Novel Memory Metric and Measurement Methodology for Modern Memory System," IEEE Transactions on Computers, vol. 63, no. 7, pp. 1626-1639, July. 2014.
Xian-He Sun, "C-AMAT: a data access model for the Big Data era," Communication of CCF, vol. 10, no. 6, pp. 19-22, June 2014.
Xian-He Sun and Dawei Wang, "Concurrent Average Memory Access Time," IEEE Computer, vol. 47, no. 5, pp. 74-80, May 2014.
Yu-Hang Liu and Xian-He Sun, "Reevaluating Data Stall Time with the Consideration of Data Access Concurrency," Journal Of Computer Science And Technology, vol. 30, no. 2, pp. 227-245, Mar. 2015.
Yu-Hang Liu and Xian-He Sun, ""LPM: Concurrency-driven Layered Performance Matching," in Proc. of the 44th International Conference on Parallel Processing (ICPP'15), Beijing, China, Sept. 2015.
Yu-Hang Liu and Xian-He Sun, "C2-bound: A Capacity and Concurrency driven Analytical Model for Manycore Design," in Proc. of the ACM/IEEE International Conference for High Performance Computing, Networking, Storage and Analysis 2015 (SC'15). Texas, Austin
Xian-He Sun and Yu-Hang Liu, " Utilizing Concurrency: A New Theory for Memory Wall,"in Proc. of the 29th International Workshop on Languages and Compilers for Parallel Computing (LCPC2016) (a position paper), September 2016, New York, USA.
Yuhang Liu and Xian-He Sun, " Cal: Extending data locality to consider concurrency for performance optimization," IEEE Transactions on Big Data, 4(2):273–288,2017.
Liu, Yu-Hang, and Xian-He Sun. " Evaluating the combined effect of memory capacity and concurrency for many-core chip design." ACM Transactions on Modeling and Performance Evaluation of Computing Systems (TOMPECS) 2, no. 2 (2017): 9.
Yuhang Liu and Xian-He Sun, " LPM: A systematic methodology for concurrent data access pattern optimization from a matching perspective," IEEE Transactions on Parallel and Distributed Systems, 30(11):2478–2493, 2019