In the age of big data, scientific applications are generating large volume of data, leading to an explosion of requirements and complexity to process these data. In High Performance Computing (HPC), data management is traditionally supported by the Parallel File Systems (PFS), such as Lustre, PVFS2, GPFS, etc. In big data environments, general-purpose analysis frameworks like MapReduce and Spark are popular and highly available with data storage supported by distributed file systems, such as Hadoop Distributed File Systems (HDFS). While HPC becomes more and more data intensive, Hadoop and Spark are becoming increasingly adopted in HPC environments as well. NASA, as one of the leading institute in cloud-resolving research, adopts Hadoop and Spark to analyze the data generated by its large-scale simulations of cloud-resolving models. However, Hadoop and Spark are not designed for HPC machines and they are not taking advantage of any capabilities of the extremely expensive and sophisticated technologies presented in existing supercomputers. They cannot read data from PFS. The data to be processed cannot utilize the merits of PFS and HDFS, and must be copied sequentially between the two file systems. Scientists who want to take advantage of the big data analytics available on Hadoop and Spark must copy data from parallel file systems manually. That is painfully slow process, especially those with terabytes of data. In this research, we propose a framework to enable data management, diagnosis, and visualization of cloud-resolving models in Hadoop and Spark. Our project is part of the NASA Super Cloud project. Please find more details about the Super Cloud project here.
A cloud-resolving model (CRM) is an atmospheric numerical model that can resolve clouds and cloud systems at very high spatial resolution. The NASA-Unified Weather Research and Forecasting (NU-Forecast (WRF) and Goddard Cumulus Ensemble (GCE)) are two representative models used in NCCS (NASA Center for Climate Simulation). The simulation results are stored in PFS of NCCS Discover system. HDFS, on the other hand, is used to store earth science data captured from observational devices, such as satellites and sensors, for data analytics in NCCS Data Analytics and Storage System (DASS) cluster. For data analysis, we need to read data from NCCS Discover system to the DASS cluster, combining them with observation data, and conducting data analysis, visualization, and animation.
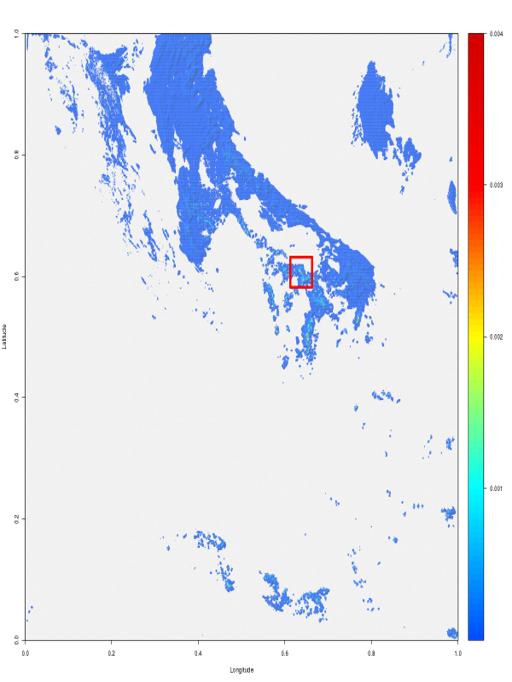
We developed a tool, named PortHadoop, to accelerate the analysis procedure. Fig. 1 demonstrates an example of visualized NU-WRF data stored in PFS of Discover. The key component in PortHadoop is the concept 'virtual block' which virtually map the files on remote PFS to HDFS and allow seamless access from Hadoop tasks. PortHadoop enables Hadoop-based application to transparently access and process remote PFS-resided data. R is the analysis tool used by NASA. To provide a more user-friendly interface and embrace R's capability and versatility in data analysis and visualization, we also extended PortHadoop to PortHadoop-R and proposed a novel strategy to enable diagnoses, sub-setting and visualization in Hadoop and Spark framework respectively.
The 'virtual block' concept helps bridge the two file systems by mapping data from parallel file systems directly onto HFDS.
An MPI-based PFS reader is proposed to adaptively read data from PFS to Hadoop memory without unnecessarily saving it to HDFS first.
Extended PortHadoop to PortHadoop-R to enrich the power of PortHadoop with the capabilities and versatility of R language in data analysis and visualization. An R interface is developed for PortHadoop.
PortHadoop-R is implemented and demonstrated with a speedup of 15x in a use case of analyzing and visualizing real NU-WRF data set in NCCS.
X. Yang, N. Liu, B. Feng, X.-H. Sun and S. Zhou, "PortHadoop: Support Direct HPC Data Processing in Hadoop," in Proc. of IEEE International Conference on Big Data (IEEE BigData 2015). Santa Clara, CA, USA, Oct. 2015. (acceptance rate: 17%)
S. Zhou, X. Yang, X. Li, T. Matsui, S. Liu, X.-H. Sun and W. Tao, "A Hadoop-Based Visualization and Diagnosis Framework for Earth Science Data," in Proc. of Big Data in the Geosciences Workshop, in conjunction with IEEE International Conference on Big Data (IEEE BigData 2015) (short paper). Santa Clara, CA, USA, Oct. 2015.
X. Yang, Y. Yin, H. Jin, and X.-H. Sun, "SCALER: Scalable Parallel File Write in HDFS," in Proc. of IEEE International Conference on Cluster Computing 2014 (Cluster'14), Madrid, Spain, Sept. 2014.
Contact:
Xian-He Sun Department of
Computer Science Illinois Institute of Technology Chicago, IL 60616
sun@iit.edu