|
|
Concurrent Average Memory Access Time (C-AMAT) |
|
|
Concurrent Average Memory Access Time (C-AMAT) is an extension of average memory access time (AMAT). It considers concurrent memory accesses and in doing so provides an accurate metric and a design and optimization tool for modern memory systems. Today's computing memory systems are organized as a memory hierarchy, where data locality is a key factor in memory performance. AMAT is the conventional tool to measure and analyze locality's influence on data access time. AMAT can be used recursively to measure the impact of locality throughout all layers of the memory hierarchy and is widely used in memory system design and optimization. However, modern memory systems are not only hierarchical but also advanced in recent years to support concurrent data accesses at each layer of the memory hierarchy. Concurrent data accesses, explained further in Section 4, allow for the processor to receive more data in a smaller amount of time compared to sequential accesses. Because of this, concurrent data accesses have become increasingly more important as memory systems are highly utilized for big data applications. AMAT does not consider concurrent memory accesses, rather it assumes that memory accesses are sequential. C-AMAT integrates data concurrency into AMAT and unifies the influence of data locality and concurrency into one formula. C-AMAT can be applied recursively to each layer of the memory hierarchy and reduces to AMAT when there exists no data concurrency. C-AMAT introduces two new parameters, hit concurrency and miss concurrency. It also introduces the notion of a pure miss, which is a miss which contains at least one pure miss cycle. A pure miss cycle is a miss cycle that does not overlap with a hit cycle. Using pure misses, C-AMAT redefines miss rate and average miss penalty of AMAT to pure miss rate and pure average miss penalty. C-AMAT reveals two important facts. 1) Reducing the number of cache misses is not important for performance improvement but reducing the number pure misses is. 2) Improving data locality may not always improve performance, thus optimizations should focus on providing a balanced improvement in both data locality and concurrency. C-AMAT is a practical and effective tool to reach such a balanced design. Like AMAT, C-AMAT finds its applications in memory system design and optimization, system configuration, FPGA utilization, and task scheduling. In turn, task scheduling and memory optimization further influence algorithm design and general system software design. Concurrent Average Memory Access Time was proposed by Xian-He Sun and Dawei Wang in the IEEE Computers Society's sponsored journal Computer. AMAT depends on three terms, hit latency, miss rate, and miss penalty. It is calculated by taking the product of miss rate and miss penalty and adding it to the hit latency. C-AMAT is formulated similar to AMAT, but considers concurrent hit and concurrent pure miss accesses. Quantitatively, C-AMAT is defined as the total memory access cycles (the total number of cycles executed in which there is at least one outstanding memory reference), represented as Concurrency is implicit in the above equation. When several memory accesses coexist during the same cycle, In addition, In order to gain meaningful insights from the C-AMAT model, C-AMAT is extended to the following: C-AMAT now includes five parameters: H(hit latency), C-AMAT redefines pMR as the number of pure misses divided by the total number of accesses. pAMP is the average number of pure miss cycles per miss access. In contrast to AMAT's MR and AMP, C-AMAT calculates miss rate and average miss penalty in terms of pure misses. Readers who are familiar with AMAT may recall that the average miss penalty of AMAT can be extended recursively to the next layer of a memory hierarchy. This recursiveness is true for C-AMAT as well. Eq. 3 shows the recurrence relation of C-AMAT1 and C-AMAT2. That is extending C-AMAT from the L1 level to L2 level. Please notice here that we have introduced a new parameter, κ1, and the impact of C-AMAT2 toward the final C-AMAT1 has been trimmed by MR1 and κ1. Here MR1 is the locality contribution as given by Eq.1 – AMAT; κ1 is the (hit/miss) overlapping contribution at the L1 level. κ1 only has one new parameter, Cm, which is the miss concurrency. Please notice that we use CM (capital M) to represent the pure concurrent misses and use Cm (little m) to represent concurrent misses. κ1 is the ratio of the number of pure miss cycles over the number of miss cycles at the L1 level. It is measurable and has a clear physical meaning. Eq. 3 is the result of a direct mathematical deduction based on the definition of C-AMAT1 and C-AMAT2, and this deduction, as well as the recursive relation, can be extended to C-AMAT2 and C-AMAT3, C-AMAT3 and C-AMAT4, etc.. Eq. 3 shows overlapping is as important as locality in reducing data access delay, while concurrency hit only increases hit bandwidth but not reduce miss penalty. It unifies and clearly presents the factors of locality, concurrency, and overlapping toward the final memory system performance.
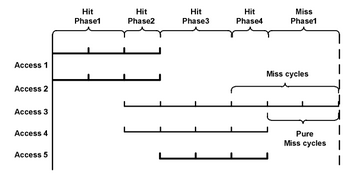
where The figure provides an example of how to calculate C-AMAT. The figure shows five accesses all of which are to the same layer of the memory hierarchy. Each access has a 3 cycle cache hit latency. If the access is a miss, there is an additional miss penalty but the value of the penalty (cycles) is uncertain. Access 1,2, and 5 are hit accesses. Access 3 has a three cycle miss penalty while Access 4 has a one cycle miss penalty. When considering the access concurrency, only Access 3 contains two pure miss cycles. Though Access 4 has 1 miss cycle, this cycle is not a pure miss cycle because it overlaps with the hit cycles of Access 5. Therefore, the miss rate of the five accesses is 0.2 according to our new definition of concurrent miss rate, instead of 0.4 of the conventional non-concurrent version. The intuition behind omitting cycles which completely overlap with hit accesses is that these miss accesses will not limit processor performance. This is because the processor can continue generating memory accesses while waiting for the missed data to return from lower memory hierarchies. Using this figure, C-AMAT is 1.6 cycles per access, whereas AMAT is 3.8 cycles per access. From the point of view of the processor, it will receive missing data every 1.6 cycles, not 3.8.
A pure miss, introduced by C-AMAT, is a miss which contains at least one pure miss cycle, which is a cycle that does not overlap with a hit cycle. The intuition behind pure miss is based on the fact that not all cache misses will cause processor stall, but rather only pure misses. C-AMAT is measured in terms of one core. Thus, even though an access may miss during a cycle, there can be another coexisting hit during the same cycle which the core can use to continue processing without waiting for the miss to be fetched. In this way, the amount of time a core must wait for data depends on how many pure misses exist, not traditional misses. Pure miss and C-AMAT, together, focus on the importance of concurrency in designing computer architecture and algorithms. Concurrent data accesses occur when there are multiple accesses being serviced in the same memory cycle. In modern memory systems, there can be multiple accesses occurring simultaneously in the same and different layer(s) of a memory hierarchy. As opposed to sequential accesses, where each access has to wait for the previous accesses to complete before accessing the memory hierarchy. Concurrent data accesses minimize an access's wait time by allowing each memory layer to serve multiple accesses in parallel. For example in a single modern cache, there can be multiple outstanding cache misses and multiple concurrent cache hits in the same memory cycle. If this cache could only process accesses sequentially, each access would be queued until the miss or hit access completes. The amount of accesses a memory layer can serve in parallel depends on hardware characteristics, such as instruction level parallelism. Data concurrency is a common research field in cache and memory optimization and is the focus of many industrial and academic researchers. APC is a performance metric and its value is the inverse of C-AMAT. The correctness and measurement of APC are well studied. Therefore, the correctness of the measurement of C-AMAT is guaranteed. At the first look, APC (Access Per Cycle) seems to be very similar to the well-known metric IPC (Instruction Per Cycle). But, in fact, the cycle used in APC is completely different with the cycle used in IPC. They are different in definitions, and different in measurement. In APC, the cycles are memory active cycles. They are not CPU cycles, as used in IPC. So, APC can also be named as APMAC (Access Per Memory Active Cycle). Also, APC uses the overlapping mode to count memory access cycles. That is, if two or more data accesses occur at the same time, the cycle only increases by one. The two differences between APC and IPC are crucial. The replacement of CPU cycle with memory active cycle separates the APC measurement with the CPU performance. The separation makes applying APC on each level of a multi-level hierarchical memory system possible, and leads to a better understanding of the matching between computing systems and memory systems. This replacement represents the shift from the traditional compute-centric thinking to a data-centric thinking in studying memory systems. Contact: Xian-He Sun
|
|
| Home | About | Contact | Sitemap | |||||||