FENCE: Fault awareness ENabled Computing Environment
As the scale of high performance computing continues
to grow, fault management is becoming a critical challenge. Recent
studies have pointed out that the MTBF of teraflop and petaflop
machines are only on the order of 10-100 hours. This situation is only
likely to deteriorate in the near future, thereby threatening the
promising productivity of large-scale systems. Checkpointing is the
conventional method for fault tolerance. However, it only deals with
failures after their occurrence through rollback. In case of one
process failure, all processes including non-faulty processes have to
be restarted from the previously saved state prior to the failure.
Thus, significant performance loss can be incurred due to the work loss
and failure recovery. Proactive approaches take preventive actions
(e.g. preemptive process migration) before failures, thereby avoiding
failures with low cost. Nevertheless, its effectiveness relies on
perfect fault prediction, which is hardly achievable in practice.
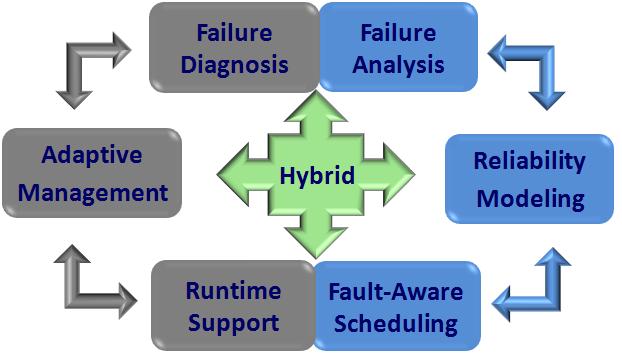
This project aims at building FENCE, a Fault awareness
ENabled Computing Environment for high performance computing. FENCE is "hybrid" by integrating
offline analysis and runtime support to enhance fault management.
Offline analysis models the possibility of faults based on historical
data and consequently facilitates intelligent system configuration and mapping; and
runtime support diagnoses runtime events and moves running jobs
away from those troublesome resources. FENCE is also "adaptive" by combining the merits
of the newly emerged proactive fault tolerant approach and the
traditional checkpointing approach. Proactive actions enable
applications to avoid anticipated faults if possible, whereas reactive
actions intend to minimize the impact of unforeseeable failures. The
following figure illustrates the major components of FENCE:
Faculty Members:
Zhiling Lan
Xian-He Sun
Graduate Students:
Yawei Li
Ziming Zheng
Wei Tang
Jin Hui
Jiexing Gu
Prashasta Gujrati
Bing Xie
Collaborators:
(ANL) Narayan Desai, Daniel Buettner, Rajeev Thakur, Susan Coghlan, Rinku Gupta and Pete Beckman
(ORNL) Byung-Hoon Park and Al Geist
(SDSC) John White and Eva Hocks
Recent Talks:
Z. Zheng,
"Reliablity-Aware Scalability Models for High Performance Computing",
HPC Resiliency Summit at Los Alamos Computer Science
Symposium 2009, Oct., 2009. [PDF ]
Z. Zheng,
"Failure Prediction with Cray Log",
The Cray Log Analysis Contest at the 1st USENIX Workshop on the Analysis of System Logs (WASL'08,
co-located with the 8th USENIX OSDI'08), December, 2008. [PDF
]
Z. Lan,
"FENCE: Fault awareness ENabled Computing Environment",
Argonne National Laboratory, May 27, 2008. [PDF]
X.-H Sun,
"Building a Fault-Aware Computing Environment",
Oak Ridge National Laboratory, Feb. 25, 2008. [PDF]
Z. Lan,
"Adaptive Fault Management for High Performance Computing",
Lawrence Livermore National Laboratory, Dec. 13, 2007. [PDF]
Z. Lan,
"Building a Fault-aware Computing Environment for High End Computing",
APART'07 Workshop (in conjunction with SC07), Nov. 11, 2007. [PDF]
Recent News:
A feature
article on our adaptive fault tolerance work in "International Science
Grid This Week"
Publications:
Y. Li and Z. Lan,
"FREM: A Fast Restart Mechanism for General Checkpoint/Restart",
to appear in the IEEE Trans. on Computers, 2010.
Z. Zheng, Z. Lan, R. Gupta, S. Coghlan, and P.
beckman,
"A Practical Failure Prediction with Location and Lead Time for Blue Gene/P",
Proc. of the 1st Workshop on Fault-Tolerance for HPC at Extreme Scale
(FTXS), in conjunction with DSN'10, 2010.
Z. Lan, J. Gu, Z. Zheng, R.
Thakur, and S. Coghlan,
"A Study of Dynamic Meta-Learning for Failure Prediction in Large-Scale
Systems"
Journal of Parallel and Distributed Computing (JPDC),
2010. [PDF]
W. Tang, N. Desai, D. Buettner, and Z. Lan,
"Analyzing and Adjusting User Runtime Estimates to Improve Job Scheduling on Blue Gene/P",
Proc. of IPDPS'10, 2010. [Best Paper Award]
Z. Lan, Z. Zheng, and Y. Li,
"Toward Automated Anomaly Identification in Large-Scale Systems",
IEEE Trans. on Parallel and Distributed Systems, Feb., 2010.
Z. Zheng and Z. Lan,
"Reliability-Aware Scalability Models for High Performance Computing",
Proc. of IEEE Cluster'09, 2009.
W. Tang, Z. Lan, N. Desai,
and D. Buettner,
"Fault-Aware Utility-Based Job Scheduling on Blue Gene/P Systems",
Proc. of IEEE Cluster'09, 2009.
Y. Li, Z. Lan, P. Gujrati, and X. Sun,
"Fault-Aware Runtime Strategies for High Performance Computing",
IEEE Trans. on Parallel and Distributed Systems , vol.
20(4), pp. 460-473, 2009.
Z. Zheng, Z. Lan,
B-H. Park,
and A. Geist,
"System Log Pre-processing to Improve Failure Prediction",
Proc. of DSN'09, 2009. [PDF]
Ziming Zheng, Rinku Gupta, Zhiling Lan, and Susan Coghlan,
"FTB-enabled Failure Prediction for Blue Gene/P Systems",
Proc. of SC'09 (research poster), 2009.
H. Jin, X.-H. Sun, B. Xie and Y. Chen,
"An Implementation and Evaluation of Memory-based Checkpointing",
Proc. of SC'09 (research poster), 2009.
Z. Zheng and Z. Lan,
"Reliability-Aware Scalability Models for High Performance Computing",
Proc. of IEEE Cluster'09, 2009.
W. Tang, Z. Lan, N. Desai,
and D. Buettner,
"Fault-Aware Utility-Based Job Scheduling on Blue Gene/P Systems",
Proc. of IEEE Cluster'09, 2009.
Z. Lan, Z. Zheng, and Y. Li,
"Toward Automated Anomaly Identification in Large-Scale Systems",
to appear in IEEE Trans. on Parallel and Distributed Systems, 2009.
Y. Li, Z. Lan, P. Gujrati, and X. Sun,
"Fault-Aware Runtime Strategies for High Performance Computing",
IEEE Trans. on Parallel and Distributed Systems , vol.
20(4), pp. 460-473, 2009.
Z. Zheng, Z. Lan,
B-H. Park,
and A. Geist,
"System Log Pre-processing to Improve Failure Prediction",
Proc. of DSN'09, 2009. [PDF]
H. Jin, X. Sun, Z. Zheng, Z. Lan and B. Xie,
"Performance under Failures of DAG-based Parallel Computing",
Proc. of CCGrid'09, 2009. [PDF]
B-H. Park, Z. Zheng, Z. Lan, and A. Geist,
"Analyzing Failure Events on ORNL's Cray XT4",
Proc. of SC'08 (research poster), 2008.
J. Gu, Z. Zheng, Z. Lan, J. White, E. Hocks, and
B-H. Park,
"Dynamic Meta-Learning for Failure Prediction in Large-scale Systems: A Case Study",
Proc. of ICPP'08 , 2008. [PDF]
Z. Lan and Y. Li,
"Adaptive Fault Management of Parallel Applications for High Performance Computing",
IEEE Trans. on Computers ,vol. 57(12), pp. 1647-1660,
2008.
Z. Lan, Y. Li, Z. Zheng, and P. Gujrati,
"Enhancing Application Robustness through Adaptive Fault Tolerance",
Proc. of the NSFNGS Workshop (in conjunction with IPDPS'08), 2008. [PDF]
X. Sun, Z. Lan, Y. Li, H. Jin, and Z. Zheng,
"Towards a Fault-Aware Computing Environment",
Proc. of High Availability and Performance Computing Workshop,, 2008.
M. Wu, X.-H. Sun, and H. Jin,
"Performance under Failure of High-End Computing",
Proc. of SC'07,, 2007.
Z. Zheng, Y. Li, and Z. Lan,
"Anomaly Localization in Large-scale Clusters",
Proc. of IEEE Cluster'07, 2007. [PDF]
P. Gujrati, Y. Li, Z. Lan, R. Thakur, and
J. White,"Exploring Meta-learning to Improve Failure Prediction in Supercomputing Clusters",
Proc. of ICPP'07 , 2007. [PDF]
Y. Li, P. Gujrati, Z. Lan, and X. Sun,
"Fault-Driven Re-Scheduling for Improving System-Level Fault Resilience",
Proc. of ICPP'07 , 2007. [PDF]
Z. Lan, Y. Li, P. Gujrati, Z. Zheng, R.
Thakur, and J. White, "A Fault Diagnosis and Prognosis Service for TeraGrid Clusters",
Proc. of TeraGrid'07 , 2007. [PDF]
Y. Li and Z. Lan,
"Using Adaptive Fault Tolerance to Improve Application Robustness on the TeraGrid",
Proc. of TeraGrid'07 , 2007. [PDF]
Y. Li and Z. Lan,
"Exploit Failure Prediction for Adaptive Fault-Tolerance in Cluster Computing",
Proc. of IEEE/ACM International Symposium on Cluster Computing and the Grid (CCGrid06),
2006. [PDF]
Z. Lan and Y. Li,
"Failure-Aware Resource Selection for Grid Computing",
Proc. of IEEE Conference on Dependable Systems and networks (Fast Abstract) ,
2006. [PDF]
Contact:
Dr. Zhiling Lan (lan AT iit DOT edu)
This work is supported by US National Science Foundation.