ChronoLog: A High-Performance Storage Infrastructure for Activity and Log Workloads
HPC applications generate more data than storage systems can handle, and it is becoming increasingly important to store activity (log) data generated by people and applications. ChronoLog is a hierarchical, distributed log store that leverages physical time to achieve log ordering and reduce contention while utilizing storage tiers to elastically scale the log capacity.

Hermes: Extending the HDF Library to Support Intelligent I/O Buffering for Deep Memory and Storage Hierarchy System
To reduce the I/O bottleneck, complex storage hierarchies have been introduced.
However, managing this complexity should not be left to application developers. Hermes
is a middeware library that automatically manages buffering in heterogeneous storage
environments.
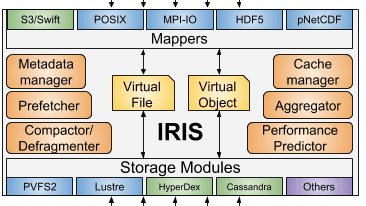
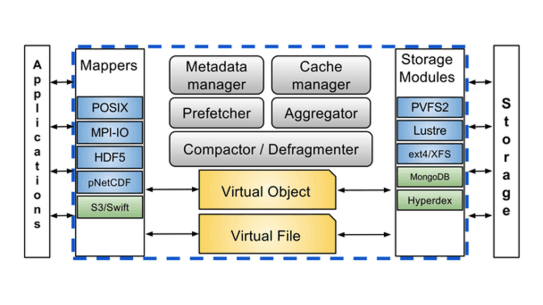
IRIS: I/O Redirection Via Integrated Storage
Various storage solutions exist and require specialized APIs and data models in order to use, which binds developers, applications, and entire computing facilities to using certain interfaces. Each storage system is designed and optimized for certain applications but does not perform well for others. IRIS is a unified storage access system that bridges the semantic gap between filesystems and object stores.