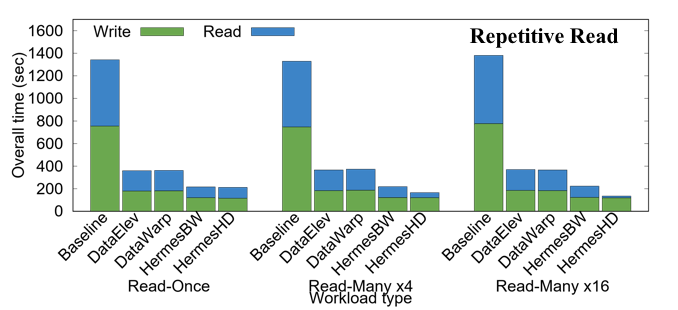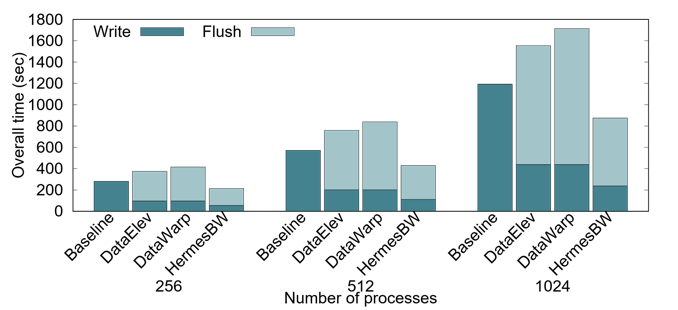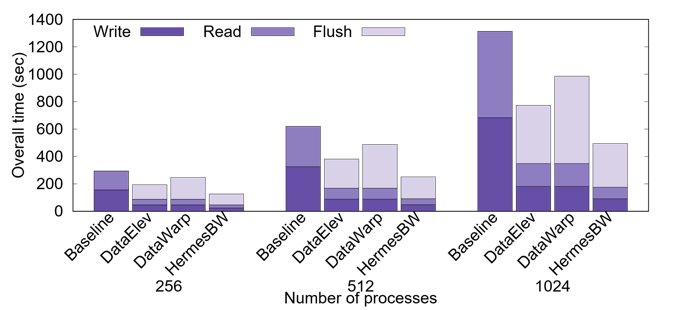Modern high performance computing (HPC) applications generate massive amounts of data. However, the performance improvement of disk based storage systems has been much slower than that of memory, creating a significant
Input/Output (I/O) performance gap. To reduce the performance gap, storage subsystems are under extensive changes, adopting new technologies and adding more layers into the memory/storage hierarchy. With a deeper memory hierarchy, the
data movement complexity of memory systems is increased significantly, making it harder to utilize the potential of the deep memory and storage hierarchy (DMSH) design.
As we move towards the exascale era, I/O bottleneck is a must to solve performance bottleneck facing the HPC community. DMSHs with multiple levels of memory/storage layers offer a feasible solution but are very
complex to use effectively. Ideally, the presence of multiple layers of storage should be transparent to applications without having to sacrifice I/O performance. There is a need to enhance and extend current software systems to support
data access and movement transparently and effectively under DMSHs.
Hierarchical Data Format (HDF) technologies are a set of current I/O solutions addressing the problems in organizing, accessing, analyzing, and preserving data. HDF5 library is widely popular within the scientific
community. Among the high level I/O libraries used in DOE labs, HDF5 is the undeniable leader with 99% of the share. HDF5 addresses the I/O bottleneck by hiding the complexity of performing coordinated I/O to single, shared files, and
by encapsulating general purpose optimizations. While HDF technologies, like other existing I/O middleware, are not designed to support DMSHs, its wide popularity and its middleware nature make HDF5 an ideal candidate to enable, manage,
and supervise I/O buffering under DMSHs.